At that time the disciples came to Jesus and asked, “Who, then, is the greatest in the kingdom of heaven?”
He called a little child to him, and placed the child among them. And he said: “Truly I tell you, unless you change and become like little children, you will never enter the kingdom of heaven. Therefore, whoever takes the lowly position of this child is the greatest in the kingdom of heaven. And whoever welcomes one such child in my name welcomes me.” (Matthew 18:1-5)
Children
lolz
We were talking about this Bible verse, because we do that thanks to the magic of an app that spits out a Bible verse every day. Laine mentioned how this seemed legit, because children really are interesting and uncommon in their faith.
“That’s why kids are curious, and why they accept new information so easily. They don’t assume they’re right about…much.”
– Laine
And…children are pretty flexible. It’s true. They’re very sure about the world, but also they approach it knowing that they probably don’t understand it. Their only job is to learn, for at least the first 14-16 years. And since they change almost daily, they learn how to adapt simply in order to…wake up every day. This has the effect of them being very sure about the world – until something tells them to change.
Adults
“Adults go all hear-no-evil because their houses of cards are confused by new input.”
– Laine again
Adults build houses of cards based on the things they think keep them safe. Layer upon layer of flimsy, and foundations built on shifting sand. These houses of cards, despite being wobbly by nature, are rigid. They have to be held perfectly still, because if you even breathe too hard on a house of cards…the whole thing topples. So adults hold their breath, and they by and large tread lightly. People with house-of-cards models hate hearing things that disagree with their view of the world – which is unfortunate, because reality, and God, very often throw new information at us. Often this information is beautiful, if only we can manage to avoid running away from it long enough to allow it in.
God is going to force change, and growth. Not a single one of us is perfect or fully formed, and we do stupid things that hurt ourselves in the name of self-protection. God protects us from ourselves, and that means sometimes we have to change even if we don’t want to – and that means that not a single one of us can actually stay perfectly still or hold our breath for any length of time.
We can fight against the wind or we can go where it takes us – but either way, a house of cards won’t survive.
Conflict, too, is necessary for change and growth. It’s necessary for the growth of each of us, and it’s also necessary for the growth of the relationships we try to stumble through while we lug our baggage along behind us. The houses of cards that represent our relationships are even more elaborate – and even more fragile.
Adapt
At some point, children grow up. They start to get their own scars and their own baggage, and they start building models of reality that don’t hurt as much as actual reality. The begin to build the house of cards, and they lose all of the flex that makes them able to have the kind of faith that can bend without collapsing at the slightest breeze.
You gotta’ keep some flex in your models.
Some things are certain. But really, “certain” just means it takes a whole lot to convince someone otherwise. God, for example, exists. He exists, and he is good, and he cares about each of us individually. That’s certain. But…actually, that just means that we’re really really sure, because there’s a lot of evidence and we’ve been over that ground a lot.
Other things, like “OpenShift is the best Kubernetes platform,” eh. Maybe we should be open to new information about that, and maybe not being certain about it would be beneficial. Maybe it’s the best for some people, or even most people – and maybe it doesn’t work at all sometimes.
You have to have a foundation that’s built on things that are real – not cards precariously stacked. And…on top of that foundation, you gotta’ keep some flex in your models. You gotta’ be open to being wrong. You have to allow for wind, and breath, and change. The alternative is ignoring reality, and ignoring God, and that’s a dangerous path to go down.
If you’ll recall our post entitled, Go: a Grumpy Old Developer’s Review, you might remember that sometimes Josh goes on legitimately amazing rants about technology and architecture. HERE IS ONE, YOU ARE ALL WELCOME.
In other words, MDM tries to create a standard database schema loaded with uniform, processed, “cleaned” data. The data is easy to query, analyze, and use for all application operations. Sounds great!
Most business have a lot of data – and if they could access that data accurately, reliably, and rapidly, it would give them a lot of insight into what their world looks like and how it’s changing. They could unify their understanding of themselves, their customers, and their partners, and become more agile (agile as in, “able to change directions quickly in response to changing conditions,” not Agile as in the development methodology).
MDM is sold as a silver bullet that will enable this master view of data, this easy querying, and this agility. But I haven’t seen that actually happen very often.
MDM Kills Agility
MDM is a tool of consistency – and consistency forces things to exist in specific ways. The real problem with MDM is then reflected when you consider that the data of a business is like the mind of the business. Imagine if your mind could no longer consider something to be valid input unless it had seen it before – as in, you could understand when you found a new variety of orange, but if you had never seen a starfruit before, you literally could not comprehend it. As one of my colleagues said,
“Building a gold data model is like nailing jello to a tree.”
MDM in its traditional, monolith definition, kills agility. Basically, it’s building a perfect utopia in which all changes have to be agreed on by everyone, and no one can move in until it’s perfect, and then no one can change ever again. Our job as technologists is not to stagnate – it’s to “deliver business value at the speed of business” (Gitlab). Businesses need to move fast, and to do that they must be able to adapt – and if IT systems don’t adapt, then IT systems slow the business down.
I’ve come across multi-year MDM projects full of ETL and data standardization meetings – and the business is finding data points that matter faster than they can be standardized. An MDM initiative that can’t move as fast as every other part of the business just slows it down, eats resources, and eventual dies a dusty death of forgottenness.
A Possible Solution: Jump-Start with a Purchased Model!
Often companies will sell a partial model of the business’s data that can be adopted more rapidly, which is typically “industry-standard” data – with claims that this will speed time to market for a MDM system. But it doesn’t.
Every organization sees the world slightly differently. This is a good thing. Individual divisions and teams within each organization will also each see the world differently. These different views mean different schemas.
Trying to fit everyone into one data model is like trying to make everyone speak exactly the same English, with no slang, no variations in tone or phrasing, and definitely no new words, connections, or ideas.
The perspective of a business, or any group, changes as the group learns and grows. Locking yourself into an old perception, or attempting to standardize via a process that takes years, is intentionally slowing down your business’s rate of adaptation and growth.
Also, it sets you up for years of arguments between teams that their view of the data – and by extension the world – is correct.
A Recommendation: Agility in Data Access Models, Not Data Storage Models
The need to have some kind of standardization so that a business’s data is useful is real. What we have seen work is more of a blended approach: spend 20% of the effort on making the data sane, and 80% of the effort on providing clear, accurate, scalable data access via APIs, in-memory databases, and occasionally Operational Data Stores (ODS). You can click on the links to learn more about each of those tools/approaches, but the basic idea is to leave the data where it is, in the format that makes sense for the team in charge of it, but provides access and views that make the data usable.
Leave the data where it is, in the format that makes sense for the team in charge of it, but provides access and views that make the data usable.
Microservices with versioned API’s, backed by legacy databases, implemented via request/response or pub/sub application communication models, are the easiest application EVAR. It’s simple to spin them up and scale them using containers and OpenShift. Using this approach, you can provide multiple data views of the data, and add more as new connections and ways of thinking appear.
If you need to do your own analytics or heavy-duty data processing/lifting, you can use a temporary or semi-permanent (but not the source of truth) data store such as an in-memory database or an ODS. Again, these are faster to set up and and more importantly faster to change than a legacy system of record, and they provide a nice balance between the speed of APIs and the performance of an enterprise database.
Conclusion: MDMs Generally Suck (Relative to Alternatives)
I would love to be wrong. I’d love to hear some new innovation that makes MDM make sense. But I’ve seen too many MDM initiatives rust out and die, and I’ve seen way too many API projects succeed wildly.
Moving stuff between Kubernetes clusters can be a pain in the butt. You have to do this when:
Migrating between container platforms, such as EKS -> AKS
Upgrading clusters when you want to upgrade in parallel (move everything from old to new) as opposed to upgrading in-place (update one cluster from old to new). This would be something like what we’ll talk about in a minute, going from OpenShift 3.x to OpenShift 4.x
Moving work/applications between clusters, e.g. two clusters in different datacenters
Migrating work between clusters requires some thought and planning, and good solid processes. Specifically, the migration from OpenShift 3.x to OpenShift 4.x requires a parallel upgrade, because there is no in-place upgrade available for all of the new goodies in RHEL CoreOS (the underlying infrastructure of the cluster). OpenShift 4.2 released recently, so we thought it would be good timing to put our migration thoughts down here. However, the advice below is generally good for any Kubernetes cluster parallel upgrade or other migration.
One of the most crucial metrics of success for an enterprise application platform is if the platform can protect: a) the applications running on it, and b) itself (and its underlying infrastructure). All threats to an application platform eventually come from something within that platform – an application can be hacked, and then it attacks other applications; or there could be a privilege escalation attack going after the underlying host infrastructure; or an application can accidentally hoard platform resources, choking out other apps from being able to run.
We work with a lot of people who are implementing Continuous Delivery. We see that when various bumps and boulders get out of the way of delivering software stably and rapidly, there’s a strong push to go very very fast. When this happens, there are often barricades put up in the name of security – because traditionally speed and security have been considered enemies. Traditional enterprise IT security would say, you can’t possibly go fast in a safe way,
There is a dream that lives in IT – it is the dream of the easy button. Push one button (or even a couple of buttons, we’re flexible!) and get immediate value. Everyone wants these easy buttons, and every software sales company wants to sell these easy buttons.
We’ve talked previously about how developers drive organizational success: they deliver the applications by which companies deliver their competitive advantages. Because they are a way for companies to deliver products to customers, those delivered applications are critically valuable. Application development is a lot like extracting gold – it creates value out of raw resources.
Application development is a lot like extracting gold – it creates value out of raw resources.
Gold, wealth, needs to have some amount of protection.
We talked in a previous post about neat stuff that was coming up in OpenShift. We wanted to follow up now that more information is available and 4.1 is GA and quickly break down some of the neatest stuff.
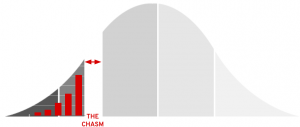
OpenShift 4 is the major version that will bring Kubernetes to being the standard platform: it provides features that let the majority of enterprises build and run the majority of their applications on an open, agile, future-ready platform.
OpenShift 4 crosses the chasm from early adopters to the standard platform for Kubernetes.
Istio (Service Mesh)
What is it: Networking upgrade for OpenShift Applications
Big Talking Point: OpenShift Service Mesh makes managing all of the services you’re building visual and clear Business Use Case: Enterprises looking to get visibility into their microservices, AppDynamics and Dynatrace customers.
Red Hat Code Ready
What is it: Containerized Application Development Environment. Tagline is “cloud-native development.”
Key Features:
Single-Click Modern IDE
Tight integration with OpenShift
Debugging containers on OpenShift is a nice experience
Business Use Case: Enterprises with poor developer IDES will appreciate CodeReady.
Competitors: IntelliJ and VSCode
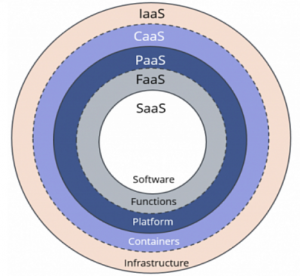
FaaS
What is it: FaaS/Serverless is an even easier, and more restricted architecture than containers or PaaS.
Serverless is an alternative to containers. Applications that would be a good fit in a simple container are an easy fit for serverless.
Knative
What is it: Kubernetes-based serverless “Application Easy Button” – just write code, forget about packaging. We talked about it in more detail here.
Key Features:
An open standard for serverless.
Build, scale, and trigger applications automatically Big Talking Point: Openshift 4’s Knative solution makes building, running, scaling, and starting applications even simpler. Business Use Case: Enterprises looking to turn their long-running (overnight) batch streams into real-time integrations should use Knative and AMQ streams on OCP
Competitors: AWS Lambda, Azure Serverless, Google Cloud Functions. K-Native provides this functionality without vendor lock-in from a single cloud provider.
The Operator Framework
What is it: intelligent automation that can manage an application by defining proper state and automate complicated application operations that using best practices.
Key Features:
Kubernetes-native application management
Choice of automation: Go, Ansible, Helm
Packaged with a Kubernetes application
Business Use Case: managing stateful applications like Kafka and databases, however new use cases show up all the time, such as managing the kubernetes cluster itself (Machine Operators)
Big Talking Point: Operators make managing complex applications in Kubernetes much easier, turning industry-standard practices into automation.
KubeVirt
What is it: Kubernetes-native virtualization. Run VMs on Kubernetes. Basically, this is VMWare for K8s.
Manage complicated, hard-to-containerize applications alongside the containerized applications that integrate with them
Business Use Case: ditch proprietary VM platforms and run you containers and VMs on one standard, open platform
What else is neat in OpenShift 4
Cluster Admin is so much easier:
Fully-automated cluster spin-up: AWS install in less than an hour
Push-button updates
Immutable Infrastructure: RHEL CoreOS are immutable and extremely strong from a security standpoint
Nodes as pets: automatic scaling and healing
Cluster can automatically add nodes as load increases
Stuff We’d Like to Get Deeper With
Theres’s a lot more coming with OpenShift that we’d like to get hands-on time with:
Windows Containers
OpenShift Cluster Management at cloud.redhat.com
Universal Base Image: https://www.redhat.com/en/blog/introducing-red-hat-universal-base-image
Quay and Clair
OpenShift: Still the Best at What it Always was Best At
OpenShift is still the platform we know and love.
Secure Kubernetes: SELinux preventing security problems like the runc vulnerability
Fully backed by Red hat, which will be even more stable and well-funded after the IBM acquisition
Enabling Digital Transformation: Containers are still the best way to transform IT, and Kubernetes is the best way to enable DevOps and Continuous Delivery
Open Hybrid Strategy: Vendor Lock-in sucks. Open standards and great partnerships.
Developers are a huge part of organizational success. Way back in 2013, Stephen O’Grady said that developers are “kingmakers” – so this idea is not new.
As a society, we’re increasingly connected – to each other, and to the businesses we choose. Those connections, and those businesses, run on software. We’ve moved to hitting a website or using an app to do business instead of picking up the phone – and even if we call a company, the person we’re talking to is definitely using software on our behalf.
Pikachu, I choose YOU.
We said that we’re more connected to the businesses we choose – and we do have significantly more choice about which businesses we use. The business’s software is part of how we make that choice – if it’s engaging and easy to understand and use, then working with the business as a customer is easier. If working with a company is easier, we’re more likely to go back. If, on the other hand, the website or app doesn’t work, or it’s confusing, we’re more likely to use one of the many alternatives that the internet allows for. Basically…
Customer service is characterized, facilitated, and proven by a company’s software.
Software driving a business’s success is also not a new idea – in fact, it’s the core concept behind the ideas of digital transformation and digital disruption. If we accept that it’s true, the next thing to consider is how to make software successful.
Software’s success is determined by how well it’s designed, built, and maintained. Great software can’t be built by mediocre developers using mediocre architecture, running on and designed for mediocre platforms. So…that means that businesses really need to know, “how do we enable our people to create amazing and engaging software?”
Software drives a business’s success – and software’s success is driven by how well it’s designed, built, and maintained.
How to Enable Developers – Technology
Enabling via Architecture
What do developers need to be successful? Well…they need several things, but first they need to understand the rules of the software they’re building: what is it intended to do? How does it communicate with other software? What APIs, services are available? Where is data permanently stored? What languages can I write it in?
These questions are all architecture. The answers should be clear and consistent, and they should allow for flexibility in implementation. They should also allow for development speed and developer familiarity – usually by using modern, standard technology with lots of community support.
Open source technology is usually the best for enabling happy developers. The communities around open source development are strong, and they’re full of skilled, passionate people who love the technology they’re contributing to – and they contribute to technology that they would love to use. Spring (Java framework), NodeJS (JavaScript run time environment), Ruby (general purpose, object-oriented programming language, like C++ and Java), MongoDB (document database), and Kafka (pub/sub messaging) are all examples of great open source architecture ingredients that developers actually like to use.
Enabling via Tools
Developers need to know what tools are at their disposal to develop, test, and run their software. They also need those tools to be kept up to date – via updates, or via new tools that accomplish what they need better, faster, or less painfully.
They need an IDE they understand – and enjoy using (we like IntelliJ, but nerd tools are something like holy flame wars, so…you do you. Laine quite happily made entire web pages in Notepad++ as a teenager, soooo…). Think about your office, or the primary tool you use to do your job – that’s an IDE for a developer. It needs to be comfortable.
They need code repositories (Git-based, Bitbucket is great), and security scanning (Sonarqube, and a dependency scanner), and test automation, ideally built in as early in the process of development as possible. They need fast build tools so they aren’t forced to stop everything and wait in order to even see if a change works (Maven, or Gradle), and automation where and how it makes sense, for builds, or deployment, or…whatever (Jenkins, or Ansible).
They need a good platform on which to run their software, ideally one that gives them the ability to self-serve…well, servers, so they don’t have to wait a week or a month or even a day to move forward once their code is ready (OpenShift).
Enabling Developers – Culture
Enabling via Processes
Confusing release processes, slow purchase processes, unclear approval processes for free tools – these are all processes that choke innovation, and worse, choke a developer’s ability to even execute. To enable developers, a business actually wants them to have some freedom to stretch out – to use their skills, and to discover new skills.
Independent of IT processes, there are also HR processes – like rules that dictate many hours must be worked, or rules that don’t “count” any work done from anywhere other than on site. IT is an art, not a formula – IT brains are constantly designing and adapting and connecting information – and then refining those designs, adaptations, and connections. Expecting, and behaving as though, X developers = Y lines of code, and Y lines of code = Z business priorities delivered causes pain and actually slows developers down.
IT is an art, not a formula.
So…there are bad processes that, if stopped or lessened or sometimes just explained will enable developers. There are also good processes – giving them a comfortable means to communicate with each other (Slack! <3), or encouraging easy ways to learn and grow and try things without repercussions.
Enabling via Support
Application developers need support – people backing them up and fighting for them, and supporting the tools they need to do their jobs in the least painful way possible. They need Architects setting architecture standards, and making sure that people talk to each other and agree about how all of the software into, out of, and within a company will interact. They need Platform Architects (sometimes called Enterprise Architects or Infrastructure Architects) setting up their platforms and making sure their apps run, and giving them access to get clear, fast feedback about their applications from those platforms.
They need people who will cut through any cultural red tape to get them the information and tools and good processes that they need. They need HR managers who support their career and their personal and professional growth. They need technical leadership who teach and advocate – new architecture patterns, how to actually use new tools, what works and definitely does NOT work between teams and in other companies. They need people explaining how to use the tools provided and giving them permission to adapt the “how” in such a way that the tool is not onerous.
They also need each other – people who are native speakers of their language, who are trying to accomplish roughly the same things in the same ways with the same barriers.
Teams Drive Organizational Success
Developers drive organizational success, but they need teams around them – supporting them, and fighting for the processes and tools that will help them be successful.
A healthy ecosystem is vitally important to developer success.
So…it isn’t actually just developers who drive organizational success – it’s teams. Teams centered around development, and enabling that development, but…definitely teams.
Successful businesses have successful software. Successful software is made by enabled developers. However, the truth of the matter is that because we are all so connected, no one exists in a vacuum. Developers need architects, and infrastructure people, and leadership (HR and technical, along with vision setters and vision communicators), and cutters of red tape, and purchasers of tools, and each other to truly be successful.
Our Pair Programming Experience – or, the first time we nerded out together and learned a ton
Pair programming is an agile software development technique in which two programmers work together at one workstation. One, the driver, writes code while the other, the observer or navigator, reviews each line of code as it is typed in. The two programmers switch roles frequently. (Wikipedia)
Why explain our experience?
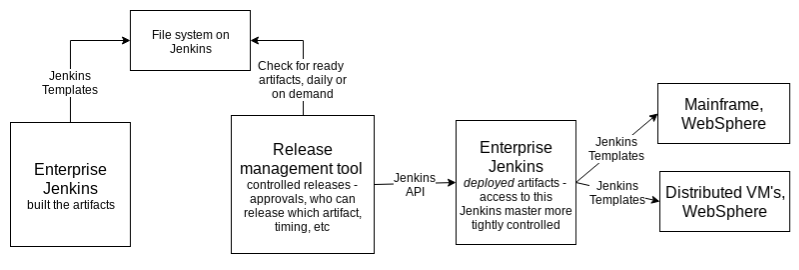
At the end of 2017, we were both OpenShift Architects at our last employer. We were working on integrating the new-to-us platform with the existing processes of the organization – especially the build, deployment, and release processes. Most of the applications on OpenShift would be Java applications, and all Java builds were done with Jenkins. There was a release management tool that was written in-house serving as a middle layer to control deployments and releases.
Build and deployment when we started, mostly to WebSphere on a mainframe or WebSphere on distributed VM’s.
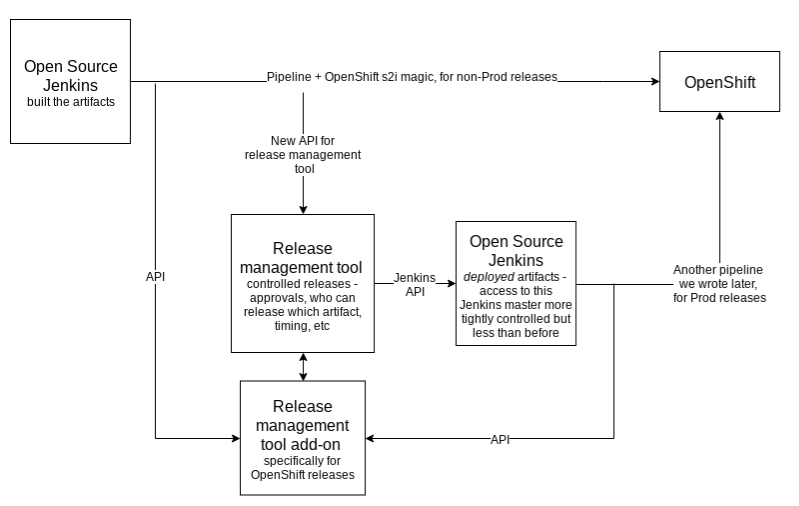
We (the organization) were also in the middle of transitioning from enterprise Jenkins + templates to open source Jenkins + pipelines. There were only a handful of people in the very large IT division who even knew how to write a pipeline – and we took on writing the pipelines (and shared libraries) that would prove out a default implementation of building and releasing to OpenShift. We knew this would be a huge challenge – if done properly, the entire company could run their OpenShift deploys on this pipeline, and it could be improved and grown as more people contributed to it via the internal open source culture that we were building.
While we figured out what to do, the pipeline just went straight from (the new, open source version of) Jenkins to OpenShift. POC FTW!
We ended up doing this via pair programming – because we work really well together, mostly. However, because we’re both technology nerds and also people/culture nerds, and because pair programming has some push-back from more traditional organizations, we wrote down the benefits we saw.
I know some stuff, and you know some stuff, but basically we’re both noobs…
We were BOTH the little turtle…
The team Laine was assigned to was the team that oversaw Jenkins administration and the build process, along with the in-house release management tool – but she’d only been on that team for about 4 months. She knew more about Jenkins than Josh, but….not by much.
Josh was the one who spearheaded bringing OpenShift into the company, and so he knew a lot of the theory of automating OpenShift deploys and had a rough idea of what the process as a whole should look like.
…basically, neither of us really knew how to do what we set out to do, and actually we didn’t intend to do something that fell into the realm of pair programming. We just already relied on each other for many things, including understanding and processing information, and we both deeply loved OpenShift and saw its potential for the company we also loved. We were determined to do as much as we possibly could to help it be successful.
What We Actually Did
Mostly our plan was to just…try stuff. We followed the definition of pair programming above some of the time – we took turns writing while the other focused more on review, catching problems, and planning the next steps. This was awesome, because we caught problems early just by keeping an eye on each other’s work – like, “uhh, you spelled ‘deploy’ D-E-P-L-Y, that’s not gonna’ work…”
Taking turns doing the actual coding also allowed us to churn through research whilestill doing development. We’re both top-down thinkers, which means that we understood the steps that needed to happen without knowing quite how we would implement each step. With one of us researching while the other was coding, as soon as one coding task was complete, we could more or less start right away on the next. Given the amount of research we had to do, this was huge in speeding us up. It also allowed us to switch up what we were each doing, and not get bogged down in either research or implementation.
Why is Heath Ledger Joker on this? IDK, who cares?? <3
In addition to taking turns coding vs overseeing, we also did a lot of what might be called parallel programming – we worked closely on different aspects of the same problem at the same time. This was also highly effective, but it required us to be very much on the same page about what we were doing. We did this mostly off-hours, via Slack communication, so…it wasn’t always a given that we actually were on the same page.
Despite the communication hijinks, or maybe because of them (it was really funny…), this was probably the most efficient of all of the coding work we did. If we got stuck or didn’t know how to solve a problem, the other could easily figure out how to help because we were already in the code. We also bounced questions and implementation ideas off of each other (efficiently, because we didn’t need to explain the entire project!), so…something like pair solution design.
And again, up there in overall efficiency, was some pair debugging. We could put our heads together to talk through what was broken (aside from typos…), figure out why it was broken, and land more quickly at the right solution to fix it. (See also: Rubber Duck Debugging)
This is where we landed after we did our part. We advised on tweaking the process, helped implement updates where we could, and…got out of the way and let the very talented and enthusiastic contributing developers take over.
Two heads are better than one. Often, the part of development that takes the longest or is the most complicated isn’t writing the code – it’s figuring out what to do, and then figuring out what you did to break it and how to fix it.
Having a person there who understands the project as well as you do can speed up…well, literally all of that.
Higher Quality
…virtually all the surveyed professional programmers stated that they were more confident in their solutions when they pair programmed.
Pair programming provides better quality, hands down. We talked about this some already – a pair programmer can catch bugs before compiling or unit tests can, and they can catch bugs all the way from a typo to an architecture or design problem. Pair programming also requires by its very nature discussing all decisions – both design and implementation, at least at a high level.
…basically, you end up with an application where there’s been a design and code review for literally every aspect of the application.
Resilient Programming FTW (or, You Can Still Make Progress Even when Your Computer Dies)
We both had some laptop issues in all of this – Laine had some battery issues, and Josh had his laptop start a virus scan (slowing his computer to the point of being unusable) while he was trying to code. We got on Slack and helped the one who still had a working laptop, rather than that time just…being wasted.
Relationships, and Joy
…more than 90% stated that they enjoyed collaborative programming more than solo programming.
Best nerd celebration emoji.
Laughing at mistakes, getting encouragement (or trolling) when we did dumb stuff, nerd emoji celebration when something went well – all of these were better because we were working together.
It was just…fun. There was joy in all of it, in both the successes and the failures. And there was joy in the shared purpose of setting something that we loved up for success.
When making a pair…
There are a few things we learned that were vital to pair programming going well for us. We think that the following pieces are the most important to a successful pairing:
Trust
Without trust, you lose some of the benefit of pointing out mistakes and instead spend the time you’d gain making sure that feelings aren’t hurt. Based on our experience, we actually think that this one is the most important key to success.
Temperament
You’ll want to find someone with approximately the same temperament and, uh…bossy-ness. We went with Bossy-ness Level: Maximum, but you do you. We both push for what we think is the right solution, and we kind of enjoy arguing with each other to figure out whose solution really is right. If either of us had paired with someone who was uncomfortable with conflict, chances are it…wouldn’t have gone well.
Technical Level/Skill/Experience
Pair programming probably isn’t going to work very well with a brand new associate paired up with someone who’s been in the industry for 10 years. That’s a lot of context to explain, so while this set up is amazing for training purposes, it isn’t the most effective for software delivery.
Lack of Knowledge
Look for someone who knows something you don’t about what you’re trying to accomplish. Laine knew Jenkins and is a Google savant, and Josh knew the OpenShift theory and reads constantly – when automating releases to OpenShift, it was a good combination.
And Finally
Pair programming provides a ton of value. It speeds up development, catches bugs sooner, and aids dramatically in design and implementation. It’s also fun, which is important and sometimes forgotten about in the just deliver more world of IT.
We loved working together on this, which led to much joy in learning the deep knowledge necessary to build a pipeline the whole company could use. And, even better, it worked – teams that joined OpenShift used and improved upon what we did, and those teams implemented continuous delivery on OpenShift. We’re both very sure that we never have been that successful if we hadn’t paired up on it.